Estudo revela que os melhores modelos de aprendizado visual falham em testes básicos de identificação visual

A maioria das crianças pré-escolares passaria facilmente nesses testes
Pesquisadores da Universidade de Auburn e da Universidade de Alberta publicaram recentemente um artigo intitulado “Modelos de linguagem visual são cegos.” O estudo utilizou oito testes simples de acuidade visual para destacar as deficiências dos modelos de aprendizado visual (VLM). As tarefas incluíam contar linhas que se cruzam, identificar letras circuladas, contar formas aninhadas, entre outras. Esses testes possuem respostas objetivamente definitivas e exigem conhecimento mínimo além de formas básicas em 2D.
Para evitar que os modelos resolvessem essas tarefas por memorização, os pesquisadores geraram os testes usando código personalizado, em vez de imagens pré-existentes. Eles avaliaram quatro modelos de VLM, incluindo GPT-4o, Gemini-1.5 Pro, Sonnet-3 e Sonnet-3.5. Os resultados mostraram que nenhum dos modelos alcançou precisão perfeita, e o desempenho variou significativamente dependendo da tarefa.
Por exemplo, o modelo com melhor desempenho só conseguiu contar as linhas e colunas em uma grade em branco com menos de 60% de precisão. Em contrapartida, o Gemini-1.5 Pro se aproximou do desempenho humano ao identificar corretamente letras circuladas em 93% das vezes.
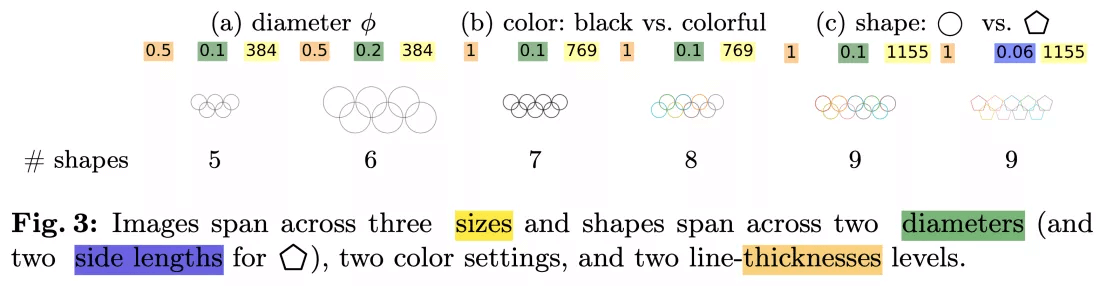
Além disso, até mesmo modificações mínimas nas tarefas resultaram em mudanças significativas de desempenho. Enquanto todos os modelos conseguiram identificar corretamente cinco círculos sobrepostos, a precisão caiu para menos de 50% quando o número de círculos aumentou para seis ou mais. Os pesquisadores teorizam que a queda na precisão pode ser devido a um viés em relação aos cinco anéis entrelaçados do logo olímpico. Alguns modelos até forneceram respostas sem sentido, como “9,” “n” ou “©” para a letra circulada em “Subdermatoglyphic.”
Esses achados destacam uma limitação significativa na capacidade dos modelos de aprendizado visual (VLMs) em lidar com tarefas abstratas visuais de baixo nível. O comportamento é reminiscente de lacunas de capacidade semelhantes em grandes modelos de linguagem, que conseguem gerar resumos de texto coerentes, mas falham em questões básicas de matemática e ortografia. Os pesquisadores levantaram a hipótese de que essas lacunas podem se originar da incapacidade dos modelos de generalizar além de seus dados de treinamento. No entanto, ajustar um modelo com imagens específicas de uma das tarefas (o teste de dois círculos tocando-se) melhorou apenas modestamente a precisão de 17 para 37 por cento, indicando que o modelo se ajusta excessivamente ao conjunto de treinamento, mas falha em generalizar.
Os pesquisadores propõem que essas lacunas de capacidade nos VLMs possam ser devido à abordagem de “fusão tardia” de integrar codificadores visuais em modelos de linguagem pré-treinados. Eles sugerem que um método de “fusão precoce”, combinando o treinamento visual e de linguagem desde o início, poderia melhorar o desempenho em tarefas visuais de baixo nível. No entanto, eles não forneceram uma análise para apoiar essa sugestão.
- Veja também: Retorno do LIFT Lab: Impulsionando a inovação no sistema financeiro com foco em criptomoedas e blockchain